淘宝SPM流量跟踪体系的研究
30 sec read
一、什么是SPM
SPM是淘宝社区电商业务(xTao)为外部合作伙伴(外站)提供的一套跟踪引导成交效果数据的解决方案。下面是一个跟踪点击到宝贝详情页的引导成交效果数据的SPM示例:http://detail.tmall.com/item.htm?id=3716461318&&spm=2014.123456789.1.2 其中spm=2014.123456789.1.2 便是下文所说的SPM编码。
SPM编码:用来跟踪页面模块位置的编码,标准spm编码由4段组成,采用a.b.c.d的格式(建议全部使用数字),其中,
- a代表站点类型,对于xTao合作伙伴(外站),a为固定值,a=2014
- b代表外站ID(即外站所使用的TOP appkey),比如您的站点使用的TOP appkey=123456789,则b=123456789
- c代表b站点上的频道ID,比如是外站某个团购频道,某个逛街频道,某个试用频道 等
- d代表c频道上的页面ID,比如是某个团购详情页,某个宝贝详情页,某个试用详情页 等
如果是站内,则SPM编码会有第五个参数,具体为:
- a:网站ID,每一个单独的网站(域名),分配唯一的ID,如www.taobao.com的aID为1,list.taobao.com的aID为a217f,item.taobao.com的aID为a217v,tmall是3,聚划算是608,搜索是a230r
- b:网页ID,为同一个网站下每一个网页,分配唯一的ID,页面A ID为7274553,页面BID为7289245
- c:频道ID,为网站中不同区域划分频道,每个频道分配唯一ID,
- d:产品ID,为每个频道内的每个独立产品,分配唯一ID
- e:同一个链接请求,为每次请求分配一个随机特征码,保证每次点击spm值的唯一性。
注意:spm的四位总长度32位,并且不支持%、&等特殊字符,请尽量使用英文以及数字
SPM的应用场景因为spm编码本身是有层次的,因此,我们可以:
- 单独统计spm的a部分,我们可以知道某一类站点的访问和点击情况,以及后续引导和成交情况。
- 单独统计spm的a.b部分,我们可以用来评估某一个站点的访问和点击效果,以及后续引导和成交情况。
- 单独统计spm的a.b.c部分,我们可以用来评估某一个站点上某一频道的访问和点击效果,以及后续引导和成交情况。
- 单独统计spm的a.b.c.d部分,我们可以用来评估某一个频道上某一具体页面的点击效果,以及后续引导和成交情况。
SPM的效果指标和数据查看基于SPM可以得到的效果统计指标:
- PV:通过指定spm编码引导到宝贝详情页面的PV
- UV:通过指定spm编码引导到宝贝详情页面的UV
- 支付宝成交人数:通过指定spm编码引导到宝贝详情页面的用户当天对同店商品的支付宝成交人数
- 支付宝成交笔数:通过指定spm编码引导到宝贝详情页面的用户当天对同店商品的支付宝成交笔数
- 支付宝成交金额:通过指定spm编码引导到宝贝详情页面的用户当天对同店商品的支付宝成交金额
- 客单价=支付宝成交金额/支付宝成交人数,代表通过指定spm编码引导过来的购买用户的消费能力
- 转化率=支付宝成交人数/UV,代表通过指定spm编码引导的用户最终转化为购买用户的比率
除此之外,还有许多其他参数,分别代表其他含义或者适用于其他业务统计需求。如pos代表的是位置,另外一个比较重要的参数为:scm=1003.632.1102.1
- 1003:投放系统ID,比如1003标识阿拉丁投放系统
- 632:算法ID,标识投放的具体算法
- 1102:标识投放算法的版本信息
- 1:标示投放针对的具体投放人群分类等信息
类似的跟踪方式还有凡客的体系,凡客与淘宝最主要的区别是跟踪参数ref的参数一直有继承,即是下一个点击会继承上一个点击产生ref,目前是继承到10级,然后就开始从原始的减少,一直保持10级。具体如下:
http://item.vancl.com/2810450.html#ref=hp-hp-yc-1_1-v:n|hp-hp-head-logo-v:n|s-s-c_rs_28806-1_3-6373505_Sort01_qb_000-v|hp-hp-classman-3_2-v:n
二、SPM体系有何作用
流量实现精准定位
- 流量可以标识到频道、页面、区块、位置任意层级
- 资源位的稳定唯一标识意味着效果可持续跟踪
- 位置和内容的分离标识,将土地和庄稼分开评估
运算资源消耗降低
- 通过编码的配置圈定多样的流量业务归属
- CPU运算资源的大幅度减低
建立效果评估体系
- 流量资源价值的统一评估标准
- 建立以资源位为中心的数据体系和运营体系
流量运营的宏观调控+市场经济时代
- 资源位估值和定价
- 资源位的分层管理和运营
- 资源位商业化通道和流动机制
- 资源位竞价和排期
三、如何搭建SPM体系
- 流程约定 — 通过侵入页面发布流程,规范打点过程
- 工具支持 — 提供低成本进行流量资源布点工具集
- 技术保障 — 用户点击链接时,由全局js生成标识编码,有效避免标识重复和疏漏
参考资料:页TBI-梵易-页面资源位监测和价值分析(PPT)
DataWorks数据埋点的设计及未来发展的思考
陶太郎
2017-11-01 15:40:20
浏览2529
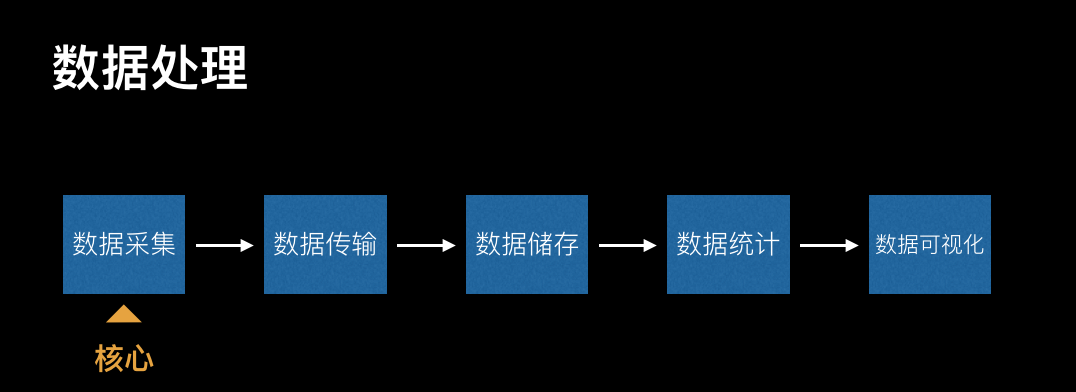
摘要: 什么是前端埋点? 马总曾经说过现在是DT时代(大数据的时代)。 数据已经成为一家公司最宝贵的财富,越来越多的互联网公司开始重视数据的应用。数据应用的过程是:数据收集 -> 数据整理(数据同步)-> 数据分析 -> 数据可视化。
什么是前端埋点?
马总曾经说过现在是DT时代(大数据的时代)。
数据已经成为一家公司最宝贵的财富,越来越多的互联网公司开始重视数据的应用。数据应用的过程是:数据收集 -> 数据整理(数据同步)-> 数据分析 -> 数据可视化。
前端埋点是用户行为数据采集领域非常重要的手段,指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。
当然前端埋点上报也不仅仅有用户行为数据的采集,还有一个很重要的领域——前端健康度分析。包括采集页面加载性能,js报错收集,接口出错上报,自定义测速等等。
为什么要进行前端埋点
埋点可以帮助分析人员获取真正需要的业务数据及其附带信息,对产品发展、业务决策和指导运营有非常重要的作用。
在不同场景下,业务人员关注的信息和角度可能不同。典型的应用场景如淘宝活动运营,以及PD和UED。前者注重来源渠道和广告效果,而后两者更在意产品本身流程和体验的优化。这就需要通过埋点采集到对应的数据,以数据为依据来做决策和判断。
打个比方,城市要提高一个路口的通过率,那必须要重新调整交通信号灯的逻辑。光看是不行的,我们需要同时拿到路口各个时间段和各个方向的车辆流动量,这就需要在相应的节点上安装摄像头和交通流量计数器。埋点同理。
DataWorks的产品和埋点需求
DataWorks是阿里集团内最大最优秀的一站式大数据平台,整合了大数据设计和开发、运维监控、数据集成、数据管理,数据安全,数据质量等产品,并打通算法平台pai,形成了完整的大数据闭环。
需求背景
目前整个DataWorks所有前端产品缺少一个统一化的埋点方案,导致产品和UED无法准确地拿到用户数据来辅助决策。
鉴于此背景,我们在为DataWorks做埋点和数据上报的时候,遇到了不小的挑战。
需要上报的数据
碰到的问题
- 首先,DataWorks是一个数据平台,包含产品15+,涉及到的页面将近50个,如果使用传统埋点方式,工作量巨大。
- 因为历史遗留问题,产品的前端技术栈不统一,有jquery、requirejs、react、angular1.x,还有一些自研的前端框架,导致无法使用统一的埋点规则进行数据采集上报。
- DataWorks的很多产品都是复杂的单页应用,而且需求交互迭代特别频繁,对用户行为数据埋点上报的拓展性和灵活性有非常高的要求。
其他业务需求
- 业务上对用户的角色、BU等信息进行分析有需求,所以在上报的数据中需要带上当前用户信息及一些产品自定义的信息。
- 能够有一个地方可以看到所有产品的PV/UV,及在线时长,流失率等指标。
- 针对定制化的需求,能够方便地对上报的数据进行抽取分析,并输出报表。
- 能够支持专有云的埋点上报。
埋点设计
设计原则
- 能够支持基础的PV/UV以及前端健康度的上报,也可以支持用户自定义上报。
- 尽量做到无痕,或者尽可能少的代码改动。降低接入埋点的工作量。
- 能够提供快速的数据抽取分析的方法。
- 可以让开发者针对不同的产品,在每次数据采集的时候,传入自定义数据。例如,用户信息,项目信息等。
- 默认全部记录,可设置抽样上报,并提供开关,关闭埋点功能。
- 统一入口,比如在公共头里统一接入埋点,再对外暴露方法,让各个产品设置自己的埋点配置。
技术选型
集团内比较成熟的两个方案:
- aplus:可以进行采集用户的PV/UV,并统计页面的在线时长,流失率等指标,而且提供了页面可视化展示各项数据。
- retcode:更专注于对前端健康度的监控和报警,并提供了灵活的自定义上报接口。另外retcode的源日志数据比较开放,更方便做后续的数据分析。
针对DataWorks的数据上报需求,我们决定使用retcode进行主要的数据上报,aplus也会默认接入(阿里的Nginx会默认在页面中插入aplus的js)。
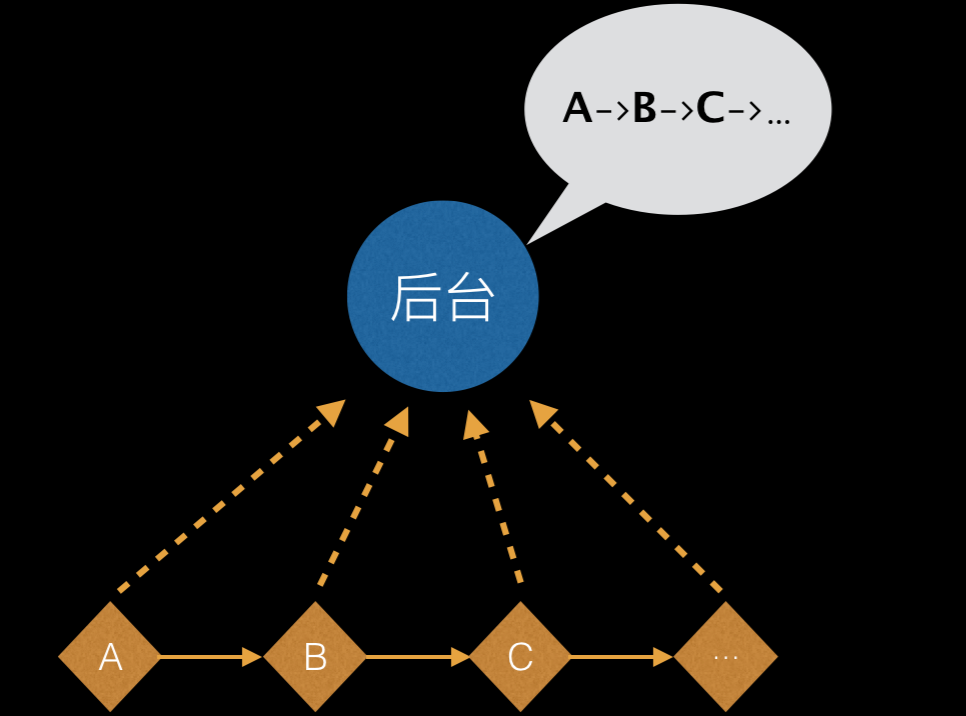
但在埋点需求中有一项aplus和retcode都无法实现,就是“所有按钮链接的点击事件”。这个需求就需要使用到“无痕埋点”(在“无痕埋点”的场景下,数据监测工具一般倾向于在监测时捕获和发送尽可能多的事件和信息,而在数据处理后端进行触发条件匹配和统计计算等工作,以较好地支持关注点变更和历史数据回溯。)。
但因为DataWorks的产品技术栈不统一,尤其当下业界在react和angular框架的无痕埋点方向上基本属于空白状态。所以我设计了一套埋点机制,来实现不同前端框架的下的无痕埋点,并将采集到的事件和数据通过retcode进行数据上报。
架构设计
从结构上划分,分为底座和插件两大块。
- 底座:负责插件的装载、数据的封装处理和上报。
- 插件:不同前端框架的埋点方案都基于规定好的数据格式开发插件,并按需插入到底座来实现埋点数据采集。
从功能上划分,底座总共分为三层,既数据采集层、数据处理层及数据传输层。

底座设计
上面讲到底座分为三层:
- 数据采集层,提供了一整套的插件接入机制。底座自身并不提供数据采集的功能,它本身只是一个容器,允许各种插件按照一定的规则插入到底座中,提供数据采集的功能。
- 数据处理层:提供了数据的规范,各个插件需要依照该数据规范把采集到的数据进行包装(例如加入各个产品配置的业务数据),然后传给数据传输层。
- 数据传输层:封装retcode进行埋点上报。
这样设计的好处是底座不负责采集,采集的工作由插件实现。而插件机制又保证了整个埋点机制的拓展性,甚至未来其他的开发者也可以基于这套底座和规范,去开发各种前端框架的埋点上报。
插件设计
我们目前开发了jQuery、react及fetch的埋点采集插件。它们前端事件和请求数据的采集方案,主要是通过Hack通用的前端框架,在事件处理函数上做文章。具体Hack的方式下面会描述。
- 优点:能够较为精确地定位到具体的选择元素以及其功能,并且可以结合框架的优势传递业务数据,更能满足我们在复杂业务场景下处理数据的需求。
- 缺点:必须要在执行用户代码之前执行我们的埋点代码。
jQuery的埋点方式:
- 第一步: 改写jQuery的事件绑定方法(如on,click,delegate等)
- 第二部: 判断如果是click,则记录selector,并对回调函数做一层封装。
- 第三部:执行回调封装的时候,会把selector传入函数内,上报上去。
注: 这里selector需要注意区分,因为有可能是通过parent或者find找到的,我们需要根据selector以及prevObject来精确查找具体的元素。
React的埋点方式:
通过改写React.createElement,其中可以拿到组件传递的Property,通过Property可以进行判断,如果含有onClick事件的话,则在此事件中进行数据的上报操作。整个过程中可以上报Component名称以及Component的父子关系。
请求采集方案:
目前对于jQuery的Ajax。主要做法是修改ajax的beforeSend函数和complete函数,来对ajax进行统一的处理及上报。
如果是fetch,则hack浏览器原生的fetch方法,来对请求进行包装,上报请求信息。
其他框架Angular、vue、backbone....
如果想使用我们的这套埋点机制,任何前端框架只需要遵循传输的数据格式,然后实现各自的点击事件采集即可。
解决的问题和优化
优化:
- 优化pv/uv数据的采集,由于用户在使用DataWorks时,页面不会关闭,导致PV/UV数据不准确。所以增加用户每日首次激活页面的时候也会进行PV/UV采集。
- jQuery插件中,减少不必要的全局事件,例如绑在body上,用来隐藏右键下拉菜单的事件。
解决掉的问题:
- retcode必须在页面文档流加载的时候引入,否则不会上报PV/UV和页面加载性能数据。这个问题很严重,因为我们的基础库是通过公共头统一引入的,这个时候文档流已经执行完毕,所以我们通过手动调用retcode提供的spm上报接口来实现PV/UV的上报。另外页面加载性能数据,也通过浏览器的PerformanceTiming API进行手动采集上报。
- jQuery的on事件绑定方法,在hack的时候需要提取guid,并赋给hack的函数,否则off的时候会找不到对应的函数。
- 推动七星阵支持retcode数据上报。
后期计划
本期主要目标在于产出数据,即实现对买点数据的采集、上报、汇总工作。后续工作可以从前端及后端数据处理两个方向进行发展。
前端方向:
- 制作浏览器插件: 基于埋点数据,开发类似Udata的浏览器插件,能够帮助PD、UED、运营对页面上用户的行为数据有个直观的认识,从而支撑他们的产品设计和决策。这个插件的数据来源可以是实时数据,也可以是离线数据。
- 数据可视化: 与集团内部的一些自定义报表工具打通,能够快速方便得进行数据可视化展现。
后端数据处理方向:
- 自动生成离线任务:DataWorks本身就是一整套的大数据平台,能够实现数据的抽取、分析和运维。后续将考虑搭建一套机制,能够自动的生成调度任务去帮用户进行数据分析。
即形成了 数据收集 -> 数据整理(数据同步)-> 数据分析 -> 数据可视化的闭环。

【云栖快讯】云栖专辑 | 阿里开发者们的20个感悟,一通百通
详情请点击
1. 项目介绍
本项目旨在以js脚本的形式,为全站web页面提供统一的日志上报接入服务,供数据平台相关同学提供标准化的数据服务。目前的上报内容包括页面pv,点击事件,页面加载性能,模块曝光与自定义事件。
日志上报脚本的兼容性为ie9或以上任意浏览器。
如果你关心上报的去向,请移步产品和数据同学应该知道的spm_id二三事。
2. 脚本接入方式
2.1 申请spm_id
spm_id的作用,是作为脚本使用者接入的唯一标记,以便在查询数据时根据spm_id得到该使用者期望的结果。每个接入日志上报脚本的项目,都有唯一的spm_id。
在准备接入脚本时,使用者应与脚本开发人员(fuqiang)进行沟通,以确定自己的spm_id。
在确定了spm_id之后,在项目html文件(或其他形式的模板)head内,埋入

此例中的spm_id为333.999。
如果需要更新页面的spm_id,可以调用reportObserver.setSPM_id方法。例如:
reportObserver.setSPM_id('123.456')
2.2 声明自定义上报的数据对象
在head标签内,声明自定义上报的数据对象:reportMsgObj 已修改为 spmReportData,详见:数据上报 by zhoubing01

2.3 引入脚本文件
在</body> 标签之前注入:

2.4 验证是否接入成功
如完成上述步骤的姿势正确,打开浏览器控制台查看network---All, 你会看到一个或多个以web? 开头的请求。 在这个请求中,你会看到2.1中设置的spm_id。
3. 上报内容
3.1 pv上报
在脚本加载后,会立即发送一条固定的pv请求到数据平台,且只发送一次。
对于前端路由,当url切换完成后,可以手动调用window.reportObserver.sendPV(), 以再次获取当前url并发送pv日志——在不希望影响现有逻辑的情况下,建议写成:

自动的上报内容包括url,refer_url, spm_id, timestamp , fts, 浏览器分辨率, 是否手机浏览。
3.2 点击上报
为了识别页面中的哪些区域需要被记录点击事件,需要脚本使用者在页面中注入特定的className。
例如,某个需要记录点击的区域显示如下
就需要在class中加入report-wrap-module, 并为该div添加id,即

这样,该report-wrap-module下的a标签点击,都会被上报。
如果有心查看点击上报发送的请求,你会发现spm_id所在的数据项,一共有四位,如333.999.xxx.7 。其中xxx为report-wrap-module的id,7即为该report-wrap-module下的第7个a标签。
自动上报的内容包括url, spm_id, 跳转url,timestamp,点击屏幕的坐标,浏览器分辨率,是否手机浏览。
3.3 性能上报
性能上报的内容为window.performance.timing中的全部字段,用于计算页面加载的各项所需时间。在脚本加载后会随pv一同上报。
3.4 模块曝光上报
模块曝光可以理解为随着滚动条的滑行,页面内指定内容出现在了视觉范围之内。这些内容的出现即称之为曝光。
为了识别哪些模块被标记为需要曝光上报,脚本使用者也需要为模块添加className。同时为该模块添加id。
仍以3.2中的模块为例,添加的className为report-scroll-module,即

现在这个模块即可以点击上报也可以滚动上报了。
自动上报的内容包括url, spm_id, timestamp, 浏览器分辨率,是否手机浏览。
3.5 自定义上报
在2.2节中有一个reportMsgObj 已修改为 spmReportData,详见:数据上报 by zhoubing01,它即为自定义上报的数据对象。
使用者在自己的脚本中执行

那么你会在浏览器network看到一条上报信息。对应的spm_id数据项形如 333.999.selfDef.xxx 。xxx与111 在上报中表示为json串:{%22event%22:%22xxx%22,%22value%22:111}。这里的value不仅限于数字,也可以是字符串,对象或其他。
上报脚本每隔1s会检查一次这个对象中的内容。如果检测到内容,会上报并将内容清除。
当有自定义内容需要立即上报时,可以使用如下的方式:

脚本会强制检查数据对象并进行上报。
3.6 错误上报(实验)
错误上报用于捕获页面加载、展现、与用户交互过程中,可以被window的error事件捕获的异常。脚本本身对错误的捕获逻辑,遵照MDN-GlobalEventHandlers.onerror,可以概述为:
用window.onerror监听运行时错误——如句法错误,各种handler抛出的异常;
用window.addEventListener('error', func) 监听资源类加载错误——script,img等。
整个错误上报流程与其他上报方式均有所不同,可以理解为:
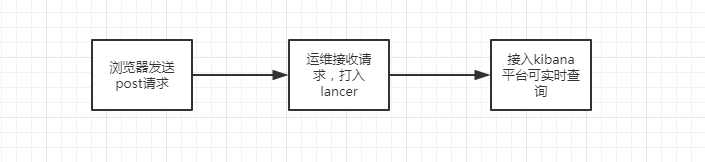
当脚本捕获到错误之后,首先将在浏览器network一栏看到dataflow.biliapi.com/log/system开头的post请求。之后数据到达kibana,可以在这里进行实时查看。关于如何在kibana上查询,可以参见这里。
3.6.0 如何开启上报脚本的错误捕获功能
在2.3节提到的reportConfig中,加入下面的逻辑:

3.6.1 如何让上报脚本捕获到runtime error
由于浏览器的同源策略限制,当页面引用的非同域的外部脚本中抛出了异常,此时本页面无权限获得这个异常详情, 将输出 Script error 的错误信息。
这就是说,如果你在x.bilibili.com下使用window.onerror对s1.xxxcdn.com/a.js的错误进行捕获,获得的错误信息将只有‘Script error’。
为此,我们需要对a.js开启“跨域资源共享机制”。
首先,在a.js引入时添加crossorigin属性:

如果你使用webpack动态引入a.js, 则可以在webpack配置里,对output.crossOriginLoading进行设置,参见这里;
其次,请求运维在a.js的相应头中添加Access-Control-Allow-Origin: * (如果已添加,可忽略)。
你可以在kibana上看到的runtime错误信息包括url,行号,列号以及错误调用堆栈信息。
3.6.2 上报脚本捕获到的错误类型
脚本将自动对资源类错误进行捕获。在kibana查询时,可以根据errorType字段获得不同种类资源对应的错误信息。errorType对应关系如下
| errorType |
错误类型 |
| 1 |
runtime |
| 2 |
script |
| 3 |
style |
| 4 |
image(当src为空时不报) |
| 5 |
audio |
| 6 |
video |
| 7 |
console |
| 8 |
try-catch |
3.6.3 try-catch上报
如果你catch到了自己的错误,那么可以交给上报脚本,脚本会帮你上传到kibana平台供实时查询。上报的方式如下:

其中,reportMsgObj为2.2节中的reportMsgObj.
如果tryCatchError传入一个对象,脚本会将该对象中的所有key-value在kibana中逐项显示;如果传入数字或字符串,那么内容默认显示在errorMsg项。
3.6.4 上报字段一览
对于runtime error,上报以下字段:
| 字段名 |
取值\含义 |
| col |
错误所在列号 |
| line |
错误所在行号 |
| errorType |
固定为1 |
| instance_id |
固定为runtime |
| level |
ERROR |
| url |
错误所在页面url |
| errorMsg |
具体的错误信息 |
| time |
ISO时间戳,YYYY-MM-DDTHH:mm:ss.sssZ |
| referrer |
页面来源 |
对于资源类错误,上报以下字段:
| 字段名 |
取值\含义 |
| errorType |
2,3,4,5,6,7, 见errorType表 |
| instance_id |
固定为resource |
| level |
ERROR |
| url |
错误所在页面url |
| errorMsg |
具体的错误信息 |
| time |
ISO时间戳,YYYY-MM-DDTHH:mm:ss.sssZ |
| referrer |
页面来源 |
对于try-catch到的错误,上报以下字段:
| 字段名 |
取值\含义 |
| app_id |
固定为:main.frontend.bilibili-log-report-seed |
| errorType |
8 |
| instance_id |
固定为trycatch |
| level |
ERROR |
| url |
错误所在页面url |
| errorMsg |
3.6.3节传入的数字或字符串 |
| time |
ISO时间戳,YYYY-MM-DDTHH:mm:ss.sssZ |
| referrer |
页面来源 |
| ... |
3.6.3节传入对象时的自定义错误信息 |
目前,可以上报错误的日志上报脚本已部署在uat环境下。
4. 报表
所有的上报都依类型存储于不同的表中,即pv一张表,性能一张表,曝光一张表,点击与自定义共用一张表。
使用者(如有操作权限)在查表时,需要根据自己的spm_id在表中进行查询。
5. 目前的接入方与spm_id
| spmid |
pc页面 |
url |
| 333.334 |
主站pc首页 |
www.bilibili.com |
| 333.788 |
主站pc播放页 |
www.bilibili.com/video/avXXXXXX/ |
| 333.337 |
主站pc搜索页 |
search.bilibili.com |
| 333.4 |
主站pc一级分区页 |
www.bilibili.com/video/XXXXXX.html |
| 333.5 |
主站pc一级分区页--动画 |
www.bilibili.com/{name} |
| spmid |
h5页面 |
url |
| 333.400 |
主站h5首页 |
m.bilibili.com/index.html |
| 333.401 |
主站h5播放页 |
m.bilibili.com/video/avXXX.html |
| 333.405 |
主站h5tag页 |
m.bilibili.com/tag/XXX(id) |
| 333.406 |
主站h5缺省页 |
m.bilibili.com/404.html |
| 333.2 |
主站h5个人空间页 |
m.bilibili.com/space/xxxxxx |
| 666.1 |
pgc作品详情落地 |
bangumi.bilibili.com/review/media/{mediaId} |