基于Node的小型NoSQL数据库设计
王海洋
haiyang5210@gmail.com
主要内容
- NoSQL是什么
- Redis和Mongo简单介绍
- 使用过程中遇到的问题
- 简洁版redis设计
- 简洁版mongo设计
- 实现过程中遇到的问题
NoSQL是什么
NoSQL 是所有非关系型数据库的统称。NoSQL不使用SQL作为查询语言,不遵循经典RDBMS原理。数据不需要固定的数据表模式,可以避免SQL中经常会用到的JOIN操作,具有水平可扩展性等特征。
什么是RDBMS
RDBMS 即关系数据库管理系统(Relational Database Management System),是将数据组织为相关的行和列来管理的系统。RDBMS要求数据的结构已明确定义,数据是致密的,并且很大程度上是一致的。它还假定建立在数据上的索引能保持一致性及统一性以提高查询的速度。
NoSQL 出现的背景
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
大数据时代
"大数据" 通常指的是那些数量巨大、难于收集、处理、分析的数据集。这类数据不仅仅增长迅速,而且半结构化和稀疏的趋势也很明显。这样一来,预定义好schema和利用关系型引用的传统数据管理技术就受到了挑战。传统的RDBMS虽然可以容忍一定程度的不规律和结构缺乏,但在松散结构的海量稀疏数据面前,这种传统的存储机制和访问方法就显得力不从心。
大数据时代
NoSQL缓解了RDBMS引发的问题并降低了处理海量稀疏数据的难度,牺牲了诸如事务完整性、数据一致性等特性,以换取数据库的高并发、高可用、高可扩展等特性。
大数据时代
Google建造了大规模可扩展的基础设施,用于支撑Google的搜索引擎和其他应用。其策略是在应用程序栈的每个层面上分别解决问题,旨在建立一套可伸缩的基础设施来并行处理海量数据。为此Google创建了一整套完备的机制,包括分布式文件系统、面向列族的数据存储、分布式协调系统和基于MapReduce的并行算法执行环境。Google 云端三大天王分別是: The Google File System, MapReduce, Bigtable。
Redis简介
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis支持的数据类型
- 字符串(最长512兆)
- 散列/哈希 2^32 - 1个元素 4294967295,超过40亿个
- 列表
- 集合
- 可排序集合
Redis示例
redis 127.0.0.1:6379> set name "yiibai.com" >> OK redis 127.0.0.1:6379> get name >> "yiibai.com"
Redis和MemoryCache的比较
- 1、运行环境不同
Redis目前官方只支持LINUX 上去行,Memcache在多个平台下都有对应的版本可以用。 - 2、支持的数据类型不同
Redis支持的数据类型比Memcache多,Memcache只支持简单的key-value结构。
Redis和MemoryCache的比较
- 3、数据持久化支持
Redis支持内存数据的持久化的,提供两种主要的持久化策略:RDB快照和AOF日志。而memcached不支持数据持久化操作。 - 4、集群管理的不同
Memcached本身并不支持分布式,Redis支持构建分布式存储。最新的Redis 引入了Master节点和Slave节点和集群的概念。
MongoDB简介(一)
MongoDB是一个开源的,基于分布式的,面向文档存储的非关系型数据库。是非关系型数据库当中功能最丰富、最接近关系数据库的。NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。MongoDB主要使用BSON格式来存储数据和传输数据。
MongoDB简介(二)
传统的关系数据库一般由数据库(database)、表(table)、记录(record)三个层次概念组成,MongoDB是由数据库(database)、集合(collection)、文档对象(document)三个层次组成。
MongoDB中的集合对应关系型数据库里的表,但是集合中没有列、行和关系概念,这体现了模式自由的特点。
JSON
JSON是一种简单的数据表示方式,它易于理解、易于解析、易于记忆。但从另一方面来说,因为只有null、布尔、数字、字符串、数组和对象这几种数据类型,所以JSON有一定局限性。例如,JSON没有日期类型,JSON只有一种数字类型,无法区分浮点数和整数,更别说区分32为和64位数字了。再者,JSON无法表示其他一些通用类型,如正则表达式、函数或日期等。
BSON
BSON(Binary Serialized Document Format)是一种类JSON的二进制形式的存储格式,简称Binary JSON。它和JSON一样, 支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和Binary、Timestamp类型等。
MongoDB示例
db.user.insert({name: 'Tom', age: 26})
>> null
db.user.find({age: {$lt: 30}})
>> [{name: 'Tom', age: 35}]
MongoDB的优点:
- 弱一致性,更能保证用户的访问速度
- 文档结构的存储方式,能够更便捷的获取数据
- 内置GridFS,支持大容量的存储
- 内置Sharding
- 第三方支持丰富
- 支持高并发,性能突出
MongoDB的缺点:
- 不支持事务操作
- 占用磁盘空间过大
- 运维工具软件少(开发和IT运维都需要考虑)
在使用过程中遇到的问题
- 环境搭建比较麻烦,配置用户,迁移数据等;
- 占用磁盘空间比较大;
- 在Node下操作MongoDB的npm组件MongoDB或mongoose操作不方便
思考和办法
- 思考:
如何在Node环境下实现一个不依赖第三方的简洁版redis和MongoDB? - 办法:
可以使用内存加文件存储的方式来实现。 - 要求:
应用重启后数据能够及时恢复,数据变更后能及时存档
小型内存数据库设计
方案1: 存取同一个文件,每5秒存盘一次 (实现简单,占用磁盘空间少;无备份文件,磁盘操作频次高,磁盘易损坏)
方案2: 每次都存不同的文件(文件多,占用磁盘空间大)
方案3: 每天一次全量备份,存在文件变动的情况下,每10秒计算一次diff然后存盘 (占用磁盘空间少,不会频繁操作磁盘;算法比较复杂)
小型内存数据库设计
- 定时任务 vs 数据变化驱动
- 串行 vs 并行处理
- 单路控制 vs 多路控制
小型内存数据库设计

小型内存数据库设计
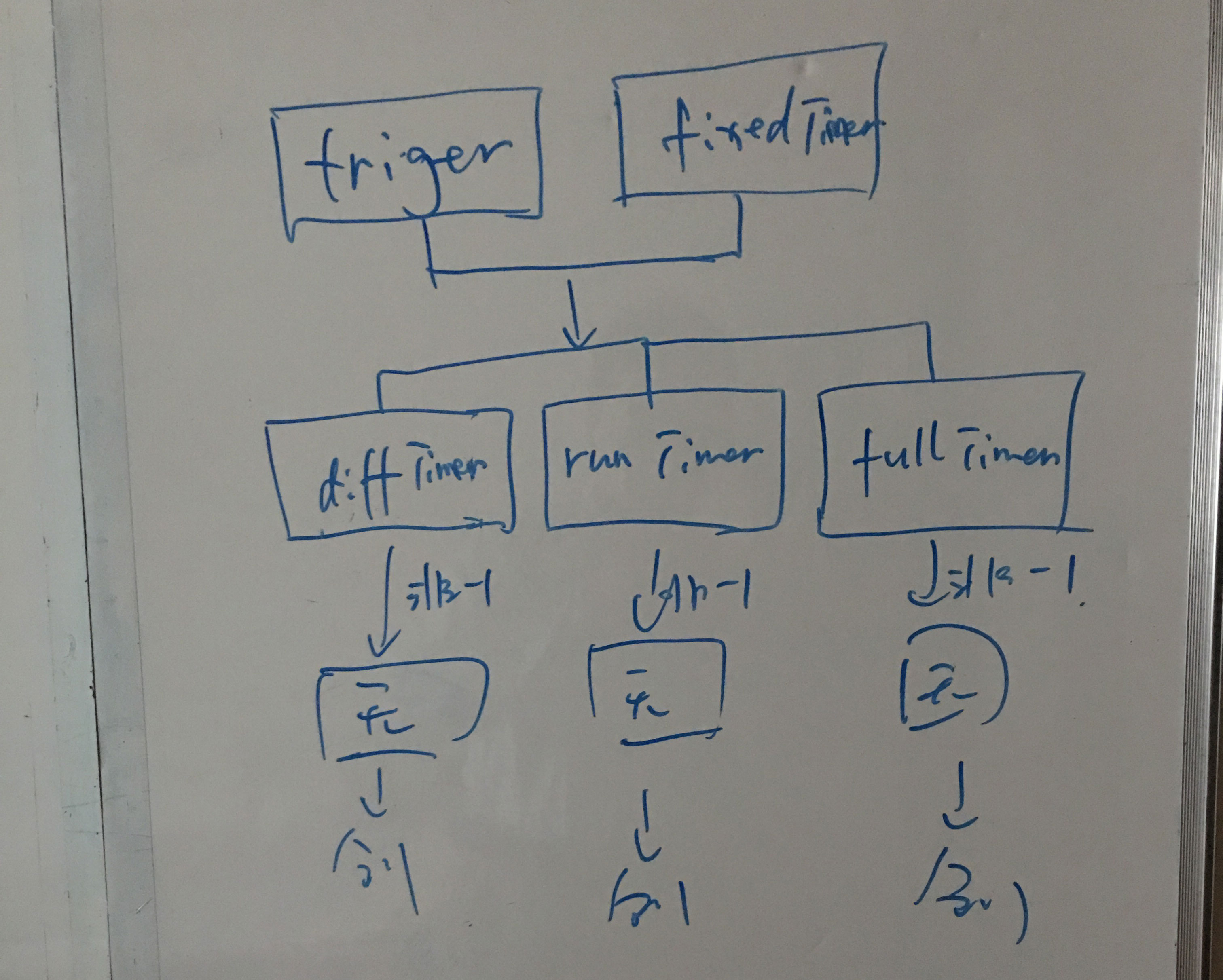
小型内存数据库设计

简洁版redis设计
1. 文档数据格式
{"_id":10096,"key":"1000000001","value":{"count": 9},
"expired":"2017-10-08 23:24:41"}
{"_id":10097,"key":"1000000002","value":{"count": 1},
"expired":"2017-10-08 24:24:41"}
2. Diff 算法
字符串比较 vs 对象深度对比
简洁版redis设计
3. API 设计(参照 Redis)
get (key) {}
set (key, value, expired) {}
clear (condition) {}
简洁版redis设计
4. 示例
var mgr = require('mongoredis')
var redis = mgr.createRedis({
dbname: 'session',
dbname: 'user',
runPeriod: 60 * 1000, // 临时缓存同步时间,默认一分钟,-1 表示关闭
quickPeriod: -1, // 差异备份时间周期,默认半小时,-1 表示关闭
fullPeriod: -1, // 全量备份时间周期,默认一天,-1 表示关闭
fixedPeriod: 30 * 1000, // 定时触发数据变动检测周期(仅redis 有此设置,mongo 无)
expiredPeriod: 30 * 60 * 1000 // 数据存储过期时间(仅redis 有此设置,mongo 无)
})
redis.set('status', 'logined', 30 * 60 * 1000)
console.log(redis.get('status'))
简洁版mongo设计
1. 文档数据格式
{"username":"tom","password":"e10adc3949","realname":"Tom",
"update_time":"2015-02-02 16:15:47","_id":"1000000001","uid":"1000000001"},
{"username":"frank","password":"e10adc3949","realname":"Frank",
"update_time":"2015-02-02 12:26:44","_id":"1000000002","uid":"1000000002"}
2. Diff 算法
JSON.stringify() vs 对象深度对比
简洁版mongo设计
3. API 设计(参照 Mongo)
getById (_id, next) {}
getAll (sort, next) {}
getItem (condition, next) {}
getItems (condition, sort, page, count, next) {}
count (condition, next) {}
insert (item, update, next) {}
update (condition, update, opt, next) {}
updateById (_id, update, next) {}
remove (condition, next) {}
简洁版mongo设计
4. 示例
var mgr = require('mongoredis')
var mongo = mgr.createMongo({
dbname: 'user',
fullPeriod: 10 * 1000,
quickPeriod: 3 * 1000
})
mongo.insert({
'username': 'guest',
'age': 20
}, function(err, result) {
res.send(result)
})
mongo.getItem(function(row) {
return String(row.username) === 'guest'
}, function(err, result) {
res.send(result)
})
实现过程中遇到的问题
- 1、condition
a. 存一个标识符?
b. 专门存一张表?
c. 直接遍历? - 2、搜索条件 1001 !== '1001'
弱类型的烦恼
实现过程中遇到的问题
- 3、condition: 条件操作符($gt,$lt,$gte,$lte) vs 函数式
db.col.find({"age": {$gt: 18}}) vs db.getItems(function(item){ return item && item.age > 18 }, next) - 4、update: 修改器($inc/$set/$unset/upsert......) vs 函数式
db.col.update({'name': 'tom'},{$set:{'state': 'married'}}) vs db.update(function(item){ return item && item.name === 'tom' }, function(item){ item.state === 'married' })
实现过程中遇到的问题
- 5、判断两个JSON对象是否相等
JSON.stringify({a:1, b:1}) !== JSON.stringify({b:1, a:1})自引用:var a = {c:1}; a.d = a; var b = {c:1}; a.d = b;来自Backbone的 isEqual 方法,针对自引用的问题做了点小改进