题目大意:
网页爬虫
Given a url
startUrl
and an interface
HtmlParser
, implement a web crawler to crawl all links that are under the
same hostname
as
startUrl
.
Return all urls obtained by your web crawler in any order.
Your crawler should:
- Start from the page:
startUrl - Call
HtmlParser.getUrls(url)to get all urls from a webpage of given url. - Do not crawl the same link twice.
- Explore only the links that are under the
same hostname
as
startUrl.

As shown in the example url above, the hostname is
example.org
. For simplicity sake, you may assume all urls use
http protocol
without any
port
specified. For example, the urls
http://leetcode.com/problems
and
http://leetcode.com/contest
are under the same hostname, while urls
http://example.org/test
and
http://example.com/abc
are not under the same hostname.
The
HtmlParser
interface is defined as such:
interface HtmlParser {
// Return a list of all urls from a webpage of given
url
.
public List<String> getUrls(String url);
}
Below are two examples explaining the functionality of the problem, for custom testing purposes you’ll have three variables
urls
,
edges
and
startUrl
. Notice that you will only have access to
startUrl
in your code, while
urls
and
edges
are not directly accessible to you in code.
Example 1:
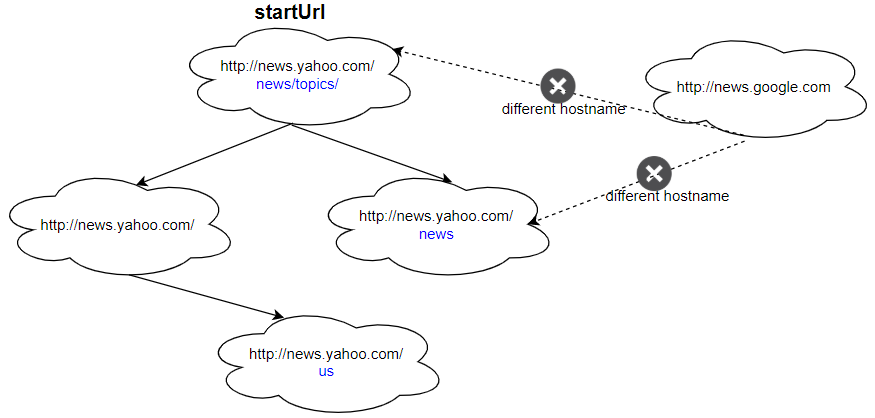
Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com", "http://news.yahoo.com/us" ] edges = [[2,0],[2,1],[3,2],[3,1],[0,4]] startUrl = "http://news.yahoo.com/news/topics/" Output: [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.yahoo.com/us" ]
Example 2:
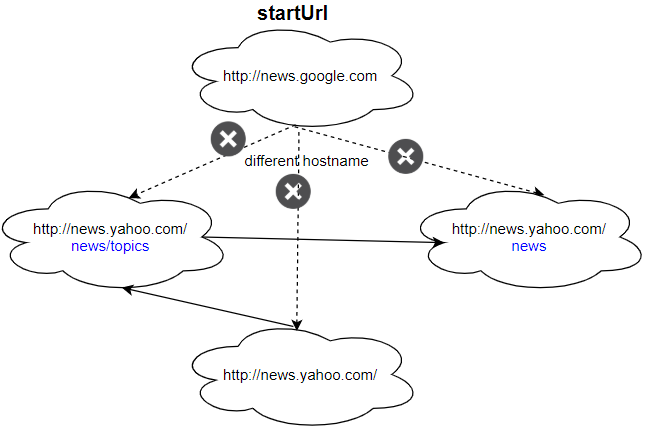
Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com" ] edges = [[0,2],[2,1],[3,2],[3,1],[3,0]] startUrl = "http://news.google.com" Output: ["http://news.google.com"] Explanation: The startUrl links to all other pages that do not share the same hostname.
Constraints:
-
1 <= urls.length <= 1000 -
1 <= urls[i].length <= 300 -
startUrlis one of theurls. - Hostname label must be from 1 to 63 characters long, including the dots, may contain only the ASCII letters from ‘a’ to ‘z’, digits from ‘0’ to ‘9’ and the hyphen-minus character (‘-‘).
- The hostname may not start or end with the hyphen-minus character (‘-‘).
- See: https://en.wikipedia.org/wiki/Hostname#Restrictions_on_valid_hostnames
- You may assume there’re no duplicates in url library.
如果想查看本题目是哪家公司的面试题,请参考以下免费链接: https://leetcode.jp/problemdetail.php?id=1236
解题思路分析:
这是一道简单的搜索类题目,不论dfs或是bfs均可解题。在搜索时要注意排重,遇到已经抓取过的页面需要跳过。
先看下dfs代码:
Set<String> res = new HashSet<>(); // 返回结果
public List<String> crawl(String startUrl, HtmlParser htmlParser) {
String host = getUrl(startUrl); // 取得域名
res.add(startUrl); // 将startUrl添加至返回结果
dfs(startUrl, host, htmlParser); // 开始dfs
return new ArrayList<>(res);
}
void dfs(String startUrl, String host, HtmlParser htmlParser){
// 取得当前页面包含的所有链接
List<String> urls = htmlParser.getUrls(startUrl);
// 通过每一个链接继续dfs
for(String url : urls){
// 如果该链接已经爬过或是与网站域名不一致时跳过
if(res.contains(url)||!getUrl(url).equals(host)){
continue;
}
// 将该链接加入返回结果
res.add(url);
// 继续dfs
dfs(url, host, htmlParser);
}
}
public String getUrl(String url) {
String[] args = url.split("/");
return args[2];
}
bfs也不难,同样是模板级的代码:
Set<String> res = new HashSet<>(); // 返回结果
public List<String> crawl(String startUrl, HtmlParser htmlParser) {
String host = getUrl(startUrl); // 取得域名
Queue<String> q = new LinkedList<>(); // bfs用的queue
res.add(startUrl); // 添加startUrl至返回结果
q.offer(startUrl); // 添加startUrl至bfs的Queue
while(q.size()>0){
String url = q.poll(); // 取得一个url
// 查看当前url包含的所有链接
List<String> urls = htmlParser.getUrls(url);
for(String u : urls){ // 循环每一个链接
// 如果该链接已经爬过或者不属于当前域名,跳过
if(res.contains(u)||!getUrl(u).equals(host)){
continue;
}
res.add(u); // 添加该链接至返回结果
q.offer(u); // 添加该链接至bfs的Queue
}
}
return new ArrayList<>(res);
}
本题两种解法用时均为8ms。
Runtime: 8 ms, faster than 41.24% of Java online submissions for Web Crawler.
Memory Usage: 50.9 MB, less than 100.00% of Java online submissions for Web Crawler.
本文转载自 https://leetcode.jp/